Die stille Achillesferse moderner Organisationen
In Behörden, Unternehmen und öffentlichen Einrichtungen hängt nahezu
jeder relevante Geschäftsprozess an einer einzigen Grundvoraussetzung:
der zuverlässigen, vollständigen und semantisch korrekten Übernahme von Meta‑Daten
und Inhalten aus schriftlichen Dokumenten.
Ob digital oder auf Papier – Dokumente sind nach wie vor die Träger der
wichtigsten Informationen im operativen Alltag. Doch ihre präzise Erfassung,
Interpretation und Überführung in digitale semantische Strukturen ist heute
eines der größten arbeitsintensiven Probleme moderner Organisationen.
Während die technische Digitalisierung – also das bloße „Scannen“ oder
OCR‑Lesen – weitgehend gelöst ist, liegt das eigentliche Problem eine Ebene
tiefer:
Die Bedeutung eines Dokuments muss verstanden werden.
Und das gelingt in der Praxis nur selten.
Das Ergebnis:
⚠️Hohe Kosten durch Datenerfassung
⚠️Verzögerte Prozesse
⚠️ menschliche Fehler
⚠️ fehlende Datenqualität
⚠️ Kostenexplosion durch Nacharbeit
⚠️ falsche Entscheidungen auf Basis unvollständiger
Informationen
Die meisten Organisationen wissen, dass dieses Problem existiert,
doch sein Ausmaß bleibt oft unsichtbar – bis etwas schiefgeht.
Warum Daten‑Übernahme so kritisch ist
Korrekte und vollständige Daten steuern heute…
- wie
schnell ein Vorgang bearbeitet werden kann
- ob
Fristen eingehalten werden
- ob
ein Prozess korrekt startet
- ob
ein Fall automatisiert oder manuell abgewickelt wird
- ob
ein Vertrag, ein Anspruch oder eine Verpflichtung überhaupt erkannt wird
In allen Branchen entscheidet die Qualität der Daten über rechtliche
Sicherheit, Effizienz, Compliance und wirtschaftliche Leistungsfähigkeit.
Alltagsbeispiele, die jeder kennt – und die das Problem drastisch zeigen
1. Elektronischer Rechtsverkehr
Durch die Einführung der Elektronischer Rechtsverkehr Verordnung (ERVV)
hat der Eingang elektronischer Dokumente bei den Justizbehörden stark
zugenommen. In der Regel ist eine umfangreiche manuelle Nachbereitung des
elektronischen Posteingangs erforderlich, wodurch die mit der Digitalisierung
erhofften Vorteile nahezu verloren gehen. Urteile, Schriftsätze,
Beweisdokumente, Anträge – alles muss erfasst, zugeordnet und in Systeme
eingepflegt werden.
Ein falsch interpretierter Satz oder ein fehlendes Schlagwort kann dazu führen,
dass:
- Fristen
falsch gesetzt werden
- Verfahren
liegen bleiben
- Rechtsmittel
nicht rechtzeitig berücksichtigt werden
- Dokumente
in der falschen Akte landen
Ein einziges fehlendes Datum kann eine komplette Prozesskette zum
Stillstand bringen.
2. Elektronische Ablagesysteme in
Unternehmen
Ablageordner voller PDF‑Dokumente sind wertlos, wenn niemand weiß:
- Was
im Dokument steht
- Welche
Vertragsdaten gelten
- Welche
Fristen einzuhalten sind
- Welche
Risiko‑ oder Compliance‑Klauseln enthalten sind
Fehlt die semantische Erfassung, bleibt die gesamte digitale Ablage ein
schwarzes Loch.
3. Belegverwaltung & Belegverarbeitung
Rechnungen, Lieferscheine, Bestellungen:
- Zahlen
werden verwechselt
- Beträge
falsch erfasst
- Lieferbedingungen
ignoriert
- Zahlungsziele
nicht erkannt
Ein einziger falsch erfasster Betrag kann zu:
- Mahnkosten
- Skontoverlust
- doppelten
Zahlungen
- Verzögerungen
im Monatsabschluss
führen.
4. Lieferscheine und Rechnungen im
operativen Alltag
Ein fehlendes Kennzeichen wie „Teillieferung“, „Rückstand“
oder „Mengenabweichung“ führt sofort zu:
- falschen
Beständen
- unnötigen
Nachbestellungen
- blockierten
Waren in der Produktion
- Eskalationen
mit Lieferanten
Die Ursache ist fast immer dieselbe:
Meta‑Daten wurden nicht erkannt oder falsch erfasst.
5. Vertragsverwaltung &
Prozesssteuerung
Moderne Verträge enthalten:
- Verpflichtungen
- Preise
- Indizes
- Fristen
- Risiken
- Leistungsbeschreibungen
- Haftungsklauseln
Doch diese Inhalte landen viel zu oft nur als PDF auf einem Fileserver
– nicht in strukturierten, maschinenlesbaren Datensätzen.
Die Folgen sind gravierend:
- automatische
Fristen laufen nicht
- Eskalationen
greifen nicht
- Risikoanalysen
sind lückenhaft
- Compliance‑Vorgaben
werden verletzt
- Vertragsstrafen
werden ausgelöst
- Nachverhandlungen
werden zu spät eingeleitet
Verträge sind wertlos, wenn ihr Inhalt im operativen Alltag nicht
gefunden, verstanden und genutzt wird.
Das eigentliche Problem: Semantische Interpretation – nicht OCR
Organisationen haben die Digitalisierung der Dokumente längst
abgeschlossen.
Was fehlt, ist die Fähigkeit, Inhalte korrekt zu interpretieren:
- Was
bedeutet der Satz?
- Welcher
Geschäftsvorfall ist gemeint?
- Welche
Frist wird ausgelöst?
- Welche
Risiken stecken darin?
- Welche
Daten müssen ins System übernommen werden?
Diese semantische Interpretation ist:
- manuell
- langsam
- teuer
- fehleranfällig
- nicht skalierbar
Und selbst wenn Menschen sorgfältig arbeiten, ist keine 100%
Vollständigkeit garantiert.
Der Preis der Unvollständigkeit
Fehlt nur ein einziges wichtiges Detail, entstehen:
- kostenintensive Rückfragen
- manuelle Nacharbeiten
- Rechts- und Compliance‑Risiken
- Prozessabbrüche
- fehlerhafte Entscheidungen
- Verletzung von Service Level Agreements
- Verlust von Transparenz und Steuerbarkeit
Ein Unternehmen kann Millionen in IT investieren –
wenn die übernommenen Meta‑Daten schlecht sind, bleibt alles Stückwerk.
Ohne saubere Meta‑Daten gibt es keine echte Digitalisierung.
Ohne semantische Interpretation gibt es keine Automatisierung.
Warum jetzt gehandelt werden muss
Unternehmen stehen heute vor drei Entwicklungen, die das Problem
verschärfen:
- Die Datenmenge explodiert
Jedes Jahr wächst die Zahl der
Dokumente, Mails, Verträge und Reports.
- Prozesse werden komplexer
Legal, Compliance, ESG, Datenschutz,
Supply‑Chain – überall steigen die Anforderungen.
- KI funktioniert nur mit sauberen
Daten
Ohne strukturierte, semantisch
verstandene Meta‑Daten bleibt KI blind.
Wer heute keine Lösung einführt, kann morgen nicht mehr mithalten.
Warum der Wunsch nach einer Lösung unausweichlich wird
Unternehmen leiden jeden Tag unter ineffizienter, unvollständiger
oder fehlerhafter Meta‑Daten‑Erfassung.
Und jeder Verantwortliche spürt zunehmend:
- Wir verlieren Zeit.
- Wir verlieren Geld.
- Wir verlieren Qualität.
- Wir verlieren Kontrolle.
- Wir verlieren Tempo gegenüber Wettbewerbern.
Die Frage lautet also nicht mehr: „Brauchen wir eine Lösung?“
sondern: „Wie lange können wir ohne Lösung noch bestehen?“
Der Faktor Mensch
Die Schwachstell der Datenerfassung aus Dokumenten ist der Mensch. Ihn
muss man entscheidend entlasten durch die Automatisierung des
Erfassungsprozesses, ohne jedoch auf seine Kompetenzen zu verzichten.
Die Aufgabe lautet also: Wie wird der Prozess der Datenerfassung
- 10‑mal schneller?
- 100 % fehlerfrei?
- 100 % vollständig?
- passgenau für das Zielsystem?
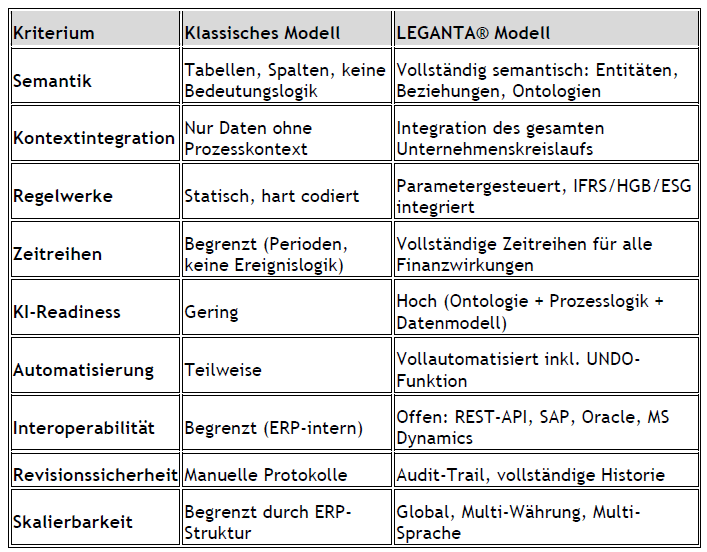
Die Lösung lautet: LSI LEGANTA® Semantic Intelligence.
Wie LSI LEGANTA® Semantic Intelligence die Datentransformation
vereinfacht
LSI ist nicht einfach ein Tool.
LSI ist ein semantisches Betriebssystem, das sprachliche Inhalte so
versteht, verarbeitet und strukturiert, wie ein erfahrener Experte – nur schneller,
präziser und skalierbar.
1. Wie LSI die Datenerfassung 10‑mal
schneller macht
- Vollautomatische Extraktion von Inhalten
LSI erkennt Strukturen, Fakten, Beziehungen, Fristen, Bedingungen,
Beträge, Rollen und Ereignisse in Echtzeit, noch bevor ein Mensch das
Dokument zu Ende gelesen hat.
- Batch‑Verarbeitung ganzer Dokumentenkorpora
Ordner mit hunderten Mails, Rechnungen oder Verträgen werden nicht mehr
manuell geprüft – LSI verarbeitet sie automatisch.
- Eliminierung von Such- und Zuordnungsaufwand
Durch die automatische Integration in das Geschäftsmodell wird der
menschliche Aufwand für:
- das
Suchen im Dokument
- das
Lesen und Interpreirdtieren
- das
Identifizieren relevanter Stellen
- das
Übertragen in Systeme
praktisch auf Null reduziert.
- Beschleunigte Freigabe- und Prüfprozesse
Durch klare, strukturierte Daten entfällt das „manuelle Prüfen“ –
Menschen sehen nur noch Ausnahmen und Abweichungen.
2. Wie LSI die Datenerfassung 100 % fehlerfrei macht
Semantische Interpretation statt Schlagwort‑Suche
LSI versteht Bedeutung, nicht nur Text. „Lieferverzug“, „verspätete
Lieferung“ und „nicht fristgerecht geliefert“ werden als dasselbe Ereignis
erkannt.
Automatische Validierung & Regelprüfung
Alle extrahierten Daten werden sofort geprüft:
- stimmen
Datumslogiken?
- passen
Fristen zu Vertragsbedingungen?
- ist
die Pflicht/Anspruch‑Beziehung konsistent?
Fehler werden nicht nur gefunden, sondern aktiv verhindert.
Kontextuelle Fehlerkorrektur
LSI erkennt: „5.000,00“ vs. „5.00000“ vs. „500,00“
selbst wenn Tippfehler oder Formatfehler im Dokument stehen.
Keine Müdigkeit, kein Versagen unter Stress
Der menschliche Faktor – Überlastung, Konzentrationsfehler, Zeitdruck –
entfällt vollständig.
3. Wie LSI 100 % Vollständigkeit
garantiert
Vollständige semantische Abdeckung jedes Dokuments
LSI liest jedes Wort, jede Zahl, jede Klausel, jedes Ereignis,
erkennt Muster und ordnet alle Elemente in das Zielsystem ein.
Erkennung relevanter Informationen auch dann, wenn sie versteckt sind
LSI findet:
- Fristen
ohne explizites Fristwort
- Risiken,
die indirekt formuliert sind
- Preisformeln,
die über mehrere Absätze verteilt sind
- Abhängigkeiten
zwischen Ereignissen und Pflichten
Vollständige Ereignis‑, Rollen‑ und Klauseltransformation
LSI verwandelt unstrukturierte Texte in:
Nichts bleibt im Dokument zurück.
Revisionssichere Dokumentation
LSI speichert:
- alle extrahierten Inhalte
→ Vollständigkeit ist jederzeit überprüfbar.
4. Wie LSI die Daten passgenau ins
Zielsystem überführt
Nahtlose Mappings auf beliebige Zielmodelle
Ob ERP, DMS, CRM, E‑Rechnungsportal oder Vertragsplattform –
LSI schreibt Datenstruktur und Semantik direkt kompatibel ins
Zielmodell.
Transformation in Prozess‑, Risiko‑ oder Vertragsdaten
LSI erzeugt exakt die Formate, die Zielsysteme brauchen:
Automatische Verlinkung & Rückverfolgbarkeit
Für jedes Datum weiß das Zielsystem:
- aus
welchem Satz es kommt
- welche
Quelle maßgeblich war
- welche
Rechte und Pflichten abhängen
Kurz: Das ist perfekte Auditfähigkeit.
🎯 Saubere Daten für KI
KI kann nur so gut arbeiten wie ihre Datengrundlage.
LSI liefert saubere, semantisch eindeutige, maschinenlesbare Daten – die
ideale Trainings- und Entscheidungsbasis.
Die Wirkung von LSI in der Zusammenfassung
|
Kriterium
|
Vor
LSI
|
Mit
LSI
|
|
Geschwindigkeit
|
langsam, manuell, Engpass Mensch
|
10× schneller, automatisiert
|
|
Fehlerquote
|
hoch, menschlich bedingt
|
nahezu 0 %, regel- und kontextbasiert
|
|
Vollständigkeit
|
unsicher, subjektiv
|
100 %, semantisch abgedeckt
|
|
Passgenauigkeit fürs Zielsystem
|
mühsam, transformieren per Hand
|
automatisch, modellgetreu
|
|
Kosten
|
hoch (Personal, Korrekturen,
Verzögerungen)
|
massive Einsparungen
|
|
Risiko
|
hoch (falsche Metadaten = falsche
Entscheidungen)
|
minimiert
|
|
Automatisierung
|
kaum möglich
|
vollumfänglich möglich
|
LSI schafft, was bisher nicht möglich war
Alle zuvor beschriebenen Probleme – manuelle Erfassung, Fehler, Lücken,
Prozessabbrüche, Kosten, Ineffizienz – werden durch LSI aufgelöst.
LSI macht aus Dokumenten strukturierte, vollständige, vertrauenswürdige
Geschäftsinformationen, die Systeme sofort verstehen und verarbeiten
können.
Warum das Zielsystem entscheidend ist
Ein Dokument – besonders ein Vertrag – enthält nicht eine einzige
Bedeutung, sondern Dutzende semantischer Perspektiven, abhängig davon,
welches System die Informationen später nutzen soll.
Ein und derselbe Satz kann je nach Zielsystem etwas völlig anderes
auslösen:
- für
die Justiz ein prozessrelevantes Ereignis
- für
Contract Intelligence eine Pflicht–Rechtsfolge–Kette
- für
SAP eine Buchung, Frist oder Indexänderung
Das bedeutet:
Dokumente müssen unterschiedlich interpretiert werden – abhängig vom
Zielsystem.
Und genau hier scheitert jede klassische OCR, jedes regelbasierte System
und fast jede Standard‑KI:
- Sie
verstehen den Geltungsraum einer Information nicht.
- Sie
wissen nicht, welcher Teil des Dokuments für welches System relevant
ist.
- Sie
können Inhalte nicht in die Zieldatenstruktur transformieren.
Die Folge: Daten kommen falsch, lückenhaft oder unbrauchbar im
Zielsystem an.
LSI durchbricht genau diese Grenze.
Wie LSI Dokumente exakt auf das Zielsystem
transformiert
LSI trennt strikt zwischen:
- Sprache verstehen (Semantik)
- Daten erzeugen
(Extraktion)
- Bedeutung systemgerecht abbilden (Transformation auf das Zielmodell)
Dadurch kann ein einziges Dokument in mehreren vollkommen
verschiedenen Strukturen gleichzeitig abgebildet werden.
Beispiel: Ein einziger Miet‑ oder
Leasingvertrag
Wir nehmen ein normales Vertragsdokument — ca. 20–40 Seiten — mit:
- Vertragsparteien
- Miet-/Leasinggegenstand
- Laufzeit
/ Beginn / Ende
- Optionen
- Indexierung
- Kündigungsfristen
- Nebenkosten
- Rechte
& Pflichten
- Leistungsstörungen
- Haftung
- Vertragsstrafen
- Übergabedokumentation
Und zeigen jetzt, wie LSI die Inhalte zielgenau in drei Systeme
transformiert.
1. Transformation für den elektronischen
Rechtsverkehr (ERV)
(gerichtliche Einreichung, Mahnwesen, Beweismittel,
Verfahrensdokumentation)
LSI extrahiert und strukturiert alle prozessrelevanten Informationen,
z. B.:
- Vertragsparteien
→ Beteiligte i.S.d. ZPO
- Fristen
→ Rechtsmittelfristen,
Fälligkeiten, Nachweisfristen
- Kündigungsregeln
→ Fristauslöser,
Ereignisabhängigkeiten
- Leistungsstörungen
→ Anspruchsgrundlagen,
Beweisrelevanz
- Vertragsstrafen
→ Schadenersatz- / Nebenforderungen
Transformation ins ERV‑Zielsystem:
|
Textinhalt
|
ERV-Datenfeld
|
|
„Vertrag beginnt am 01.03.2026“
|
Ereignis: Beginn eines
Dauerschuldverhältnisses
|
|
„Indexierung gemäß VPI jährlich“
|
Abrechnungsmodus / wiederkehrende
Verpflichtung
|
|
„Kündigungsfrist 6 Monate“
|
Fristtyp: ordentliche Kündigung;
Fristdauer: 6 Monate
|
|
„Übergabe bis spätestens
01.04.2026“
|
Erfüllungshandlung → Datum
|
LSI stellt damit sicher:
- alle
Informationen für rechtlich korrekte elektronische Vorgänge
- eindeutige
Zuordnung im ERV‑Portal
- vollständige
maschinenlesbare Verfahrensdaten
- automatische
Fristenkontrolle
2. Transformation für LCI LEGANTA®
Contract Intelligence
(vollständige Vertragsdigitalisierung, Risiko‑ und Pflichtenanalyse,
Prozess‑Trigger)
Für LCI transformiert LSI nicht nur Fakten, sondern:
- Geschäftsereignisse
- Pflichten
& Rechte
- Bedingungen
- Abhängigkeiten
- Rollen
- Risiken
- Indexmechanismen
- Ereignis‑Kaskaden
- Vertragsnutzen
& Leistungsversprechen
Transformation ins LCI‑Modell:
|
Textinhalt
|
LCI-Datenstruktur
|
|
„Der Leasingnehmer ist
verpflichtet, die Wartung jährlich durchzuführen.“
|
Pflicht: Wartung durchführen
(Zyklus: jährlich)
|
|
„Die Miete erhöht sich gemäß Index,
wenn …“
|
Ereignis: Indexschwelle
überschritten → Berechnungsparameter
|
|
„Bei verspäteter Rückgabe fällt
eine Vertragsstrafe an“
|
Risiko: Verspätete Rückgabe → Kostenformel
|
|
„Der Vermieter muss Mängel binnen
14 Tagen beheben“
|
SLA/Pflicht: Mängelbehebung 14
Tage
|
LSI ermöglicht damit:
- vollautomatische Pflichtenmodelle
- vollautomatische Risiko‑Signaturen (LRI)
- Prozess‑Trigger
für Workflow‑Automatisierung
- Nutzung
im LEGANTA® Unternehmenskreislauf
Hier entfaltet LSI seine volle Kraft:
Es versteht, wie ein Vertrag das Unternehmen steuert.
3. Transformation für SAP LCM (Lease Contract Management)
(Buchungslogik, Zahlungspläne, ROU‑Asset, IFRS 16, Laufzeiten)
SAP braucht eine völlig andere Sicht:
- Zahlungspläne
- Anfangsbewertung
- Nutzungsrechte
- Indexierungen
- Restwerte
- Vertragsänderungen
-
- implizite
und explizite Zinssätze
Transformation ins SAP‑LCM‑Modell:
|
Vertragsinhalt
|
SAP
LCM Datenpunkt
|
|
„Mietbeginn 01.03.2026“
|
Startdatum der Leasinglaufzeit
|
|
„Monatliche Rate 3.500 EUR“
|
Recurring Payment (Periodizität:
monatlich)
|
|
„Laufzeit 36 Monate“
|
Contract Term → 36
|
|
„Restwert 10.000 EUR“
|
Residual Value
|
|
„Indexierung jährlich VPI“
|
CPI‑Indexregel
|
|
„Option: Verlängerung um 12 Monate“
|
Modify
Option / Non‑lease component
|
|
„Kaution 5.000 EUR“
|
Initial Direct Cost (je nach
Systemkonfiguration)
|
LSI liefert SAP genau:
- alle
Zahlen
- alle
Konditionen
- alle
Zeitpunkte
- alle
Indexierungslogiken
- alle
lease‑relevanten Parameter
— vollständig, fehlerfrei und revisionssicher.
Warum LSI einzigartig ist
Die meisten Systeme können:
- OCR
- regelbasierte Extraktion
- einfaches Text Mining
- Schlagworterkennung
Aber kein anderes System kann:
|
Fähigkeit
|
LSI
beherrscht
|
Andere
Systeme
|
|
Text semantisch interpretieren
|
✅
|
❌
|
|
verschiedene Zielmodelle
gleichzeitig bedienen
|
✅
|
❌
|
|
vollständige Pflichten‑ &
Risiko‑Modelle erstellen
|
✅
|
❌
|
|
juristische, kaufmännische &
technische Semantik verbinden
|
✅
|
❌
|
|
Ereignis‑, Rollen‑ und
Parameterlogik extrahieren
|
✅
|
❌
|
|
Daten passgenau in ERP/DMS/ERM/ERV
überführen
|
✅
|
❌
|
|
Audit‑Trail &
Maschineninterpretation gleichzeitig liefern
|
✅
|
❌
|
LSI ist damit der entscheidende Hebel, um die Metadaten‑Krise
endgültig zu überwinden.
Fazit
LSI macht aus einem einzigen Dokument drei vollkommen verschiedene,
vollständige, fehlerfreie und systemgerechte Datensätze – gleichzeitig.
Damit wird möglich, was bislang unmöglich war:
- 10× schneller
- 100 % vollständig
- 100 % fehlerfrei
- perfekt passend zum Zielsystem